
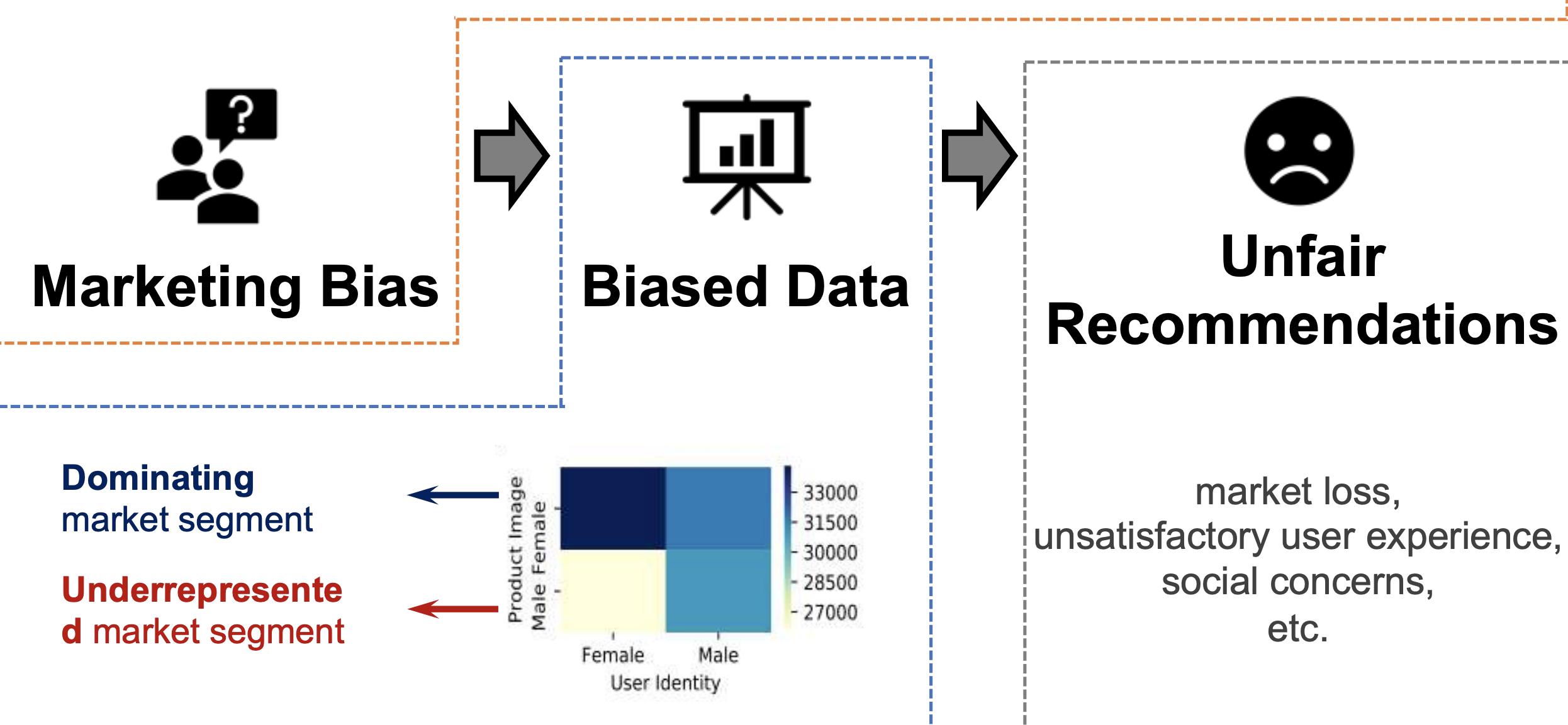
Addressing Marketing Bias in Product Recommendations
Modern collaborative filtering algorithms seek to provide personalized product recommendations by uncovering patterns in consumer-product interactions. However, these interactions can be biased by how the product is marketed, for example due to the selection of a particular human model in a product image. These correlations may result in the underrepresentation of particular niche markets in the interaction data; for example, a female user who would potentially like motorcycle products may be less likely to interact with them if they are promoted using stereotypically 'male' images. In this paper, we first investigate this correlation between users' interaction feedback and products' marketing images on two real-world e-commerce datasets. We further examine the response of several standard collaborative filtering algorithms to the distribution of consumer-product market segments in the input interaction data, revealing that marketing strategy can be a source of bias for modern recommender systems. In order to protect recommendation performance on underrepresented market segments, we develop a framework to address this potential marketing bias. Quantitative results demonstrate that the proposed approach significantly improves the recommendation fairness across different market segments, with a negligible loss (or better) recommendation accuracy.

Fine-Grained Spoiler Detection from Large-Scale Review Corpora
This paper presents computational approaches for automatically detecting critical plot twists in reviews of media products. First, we created a large-scale book review dataset from Goodreads that includes fine-grained spoiler annotations at the sentence-level, as well as book and (anonymized) user information. Second, we carefully analyzed this dataset and found that: spoiler language tends to be book-specific; spoiler distributions vary greatly across books and review authors, and spoiler sentences tend to appear in the latter part of reviews. Third, inspired by these findings, we developed an end-to-end neural network architecture to detect spoiler sentences in review corpora. Quantitative and qualitative results demonstrate that the proposed method substantially outperforms existing baselines.
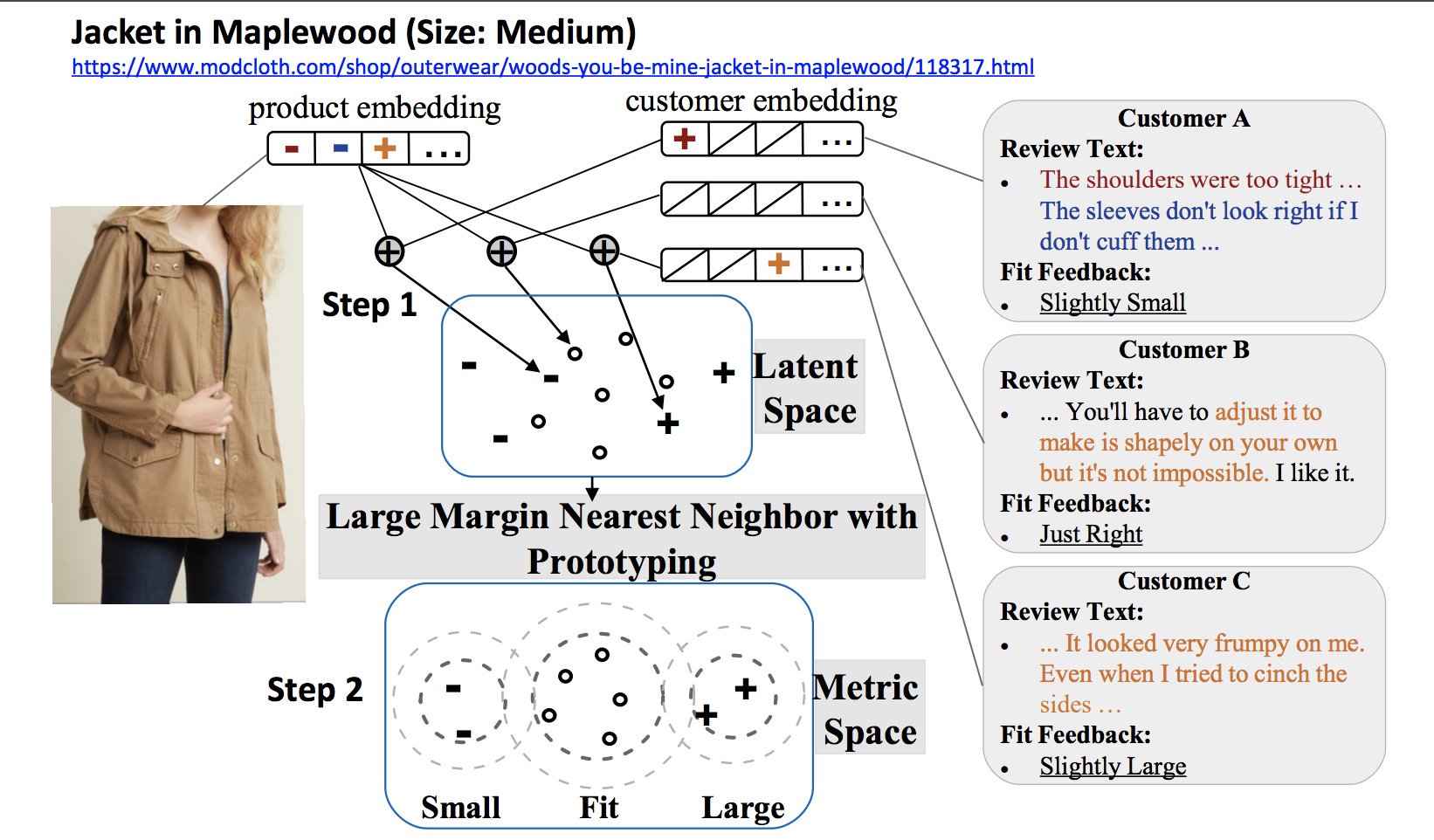
Decomposing Fit Semantics for Product Size Recommendation in Metric Spaces
Product size recommendation and fit prediction are critical in order to improve customers’ shopping experiences and to reduce product return rates. Modeling customers’ fit feedback is challenging due to its subtle semantics, arising from the subjective evaluation of products, and imbalanced label distribution. In this paper, we propose a new predictive framework to tackle the product fit problem, which captures the semantics behind customers’ fit feedback, and employs a metric learning technique to resolve label imbalance issues. We also contribute two public datasets collected from online clothing retailers.
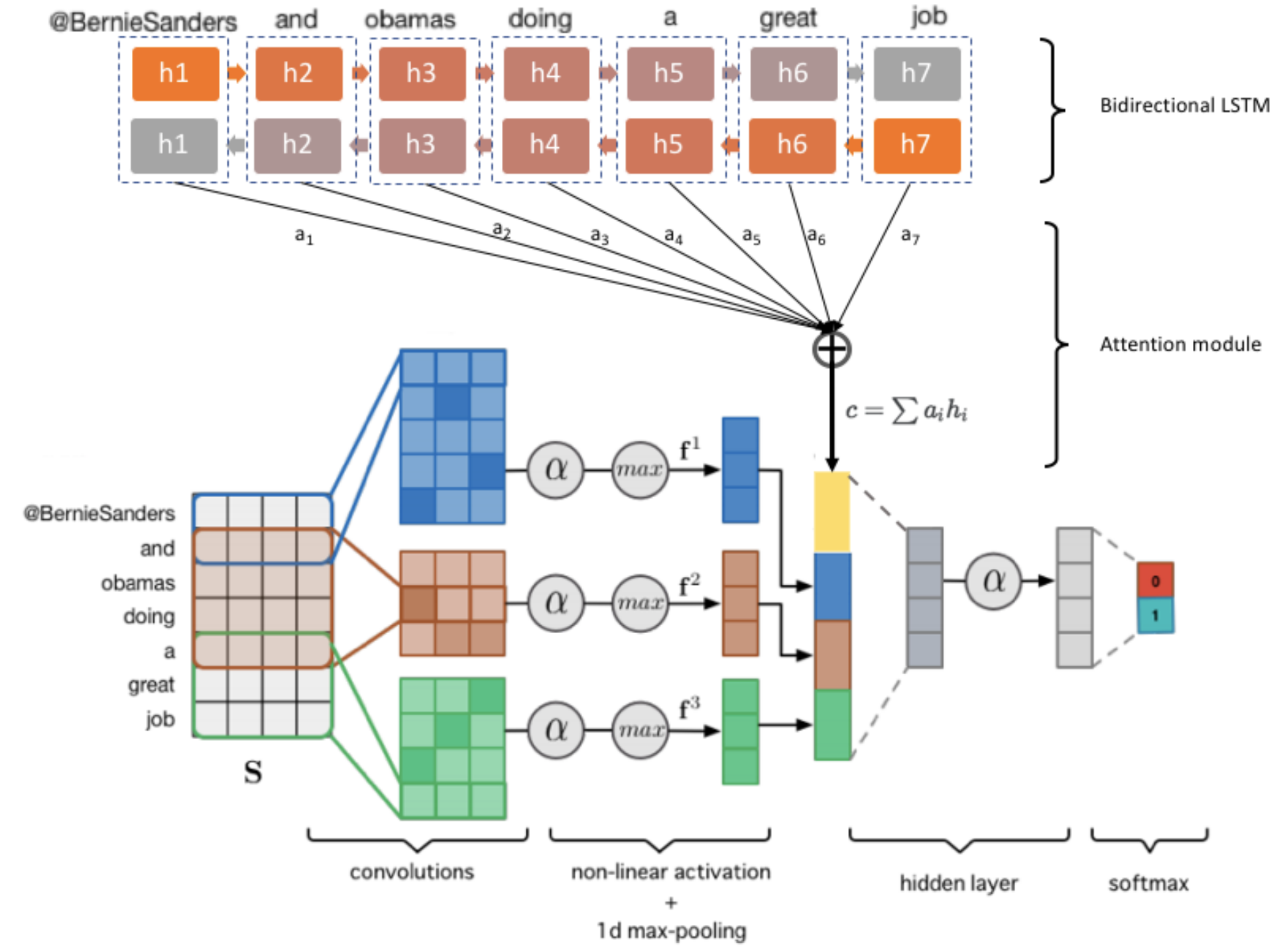
Sarcasm Detection using Hybrid Neural Network
Sarcasm Detection has enjoyed great interest from the research community, however the task of predicting sarcasm in a text remains an elusive problem for machines. Past studies mostly make use of twitter datasets collected using hashtag based supervision but such datasets are noisy in terms of labels and language. To overcome these shortcoming, we introduce a new dataset which contains news headlines from a sarcastic news website and a real news website. Next, we propose a hybrid Neural Network architecture with attention mechanism which provides insights about what actually makes sentences sarcastic. Through experiments, we show that the proposed model improves upon the baseline by ∼ 5% in terms of classification accuracy.
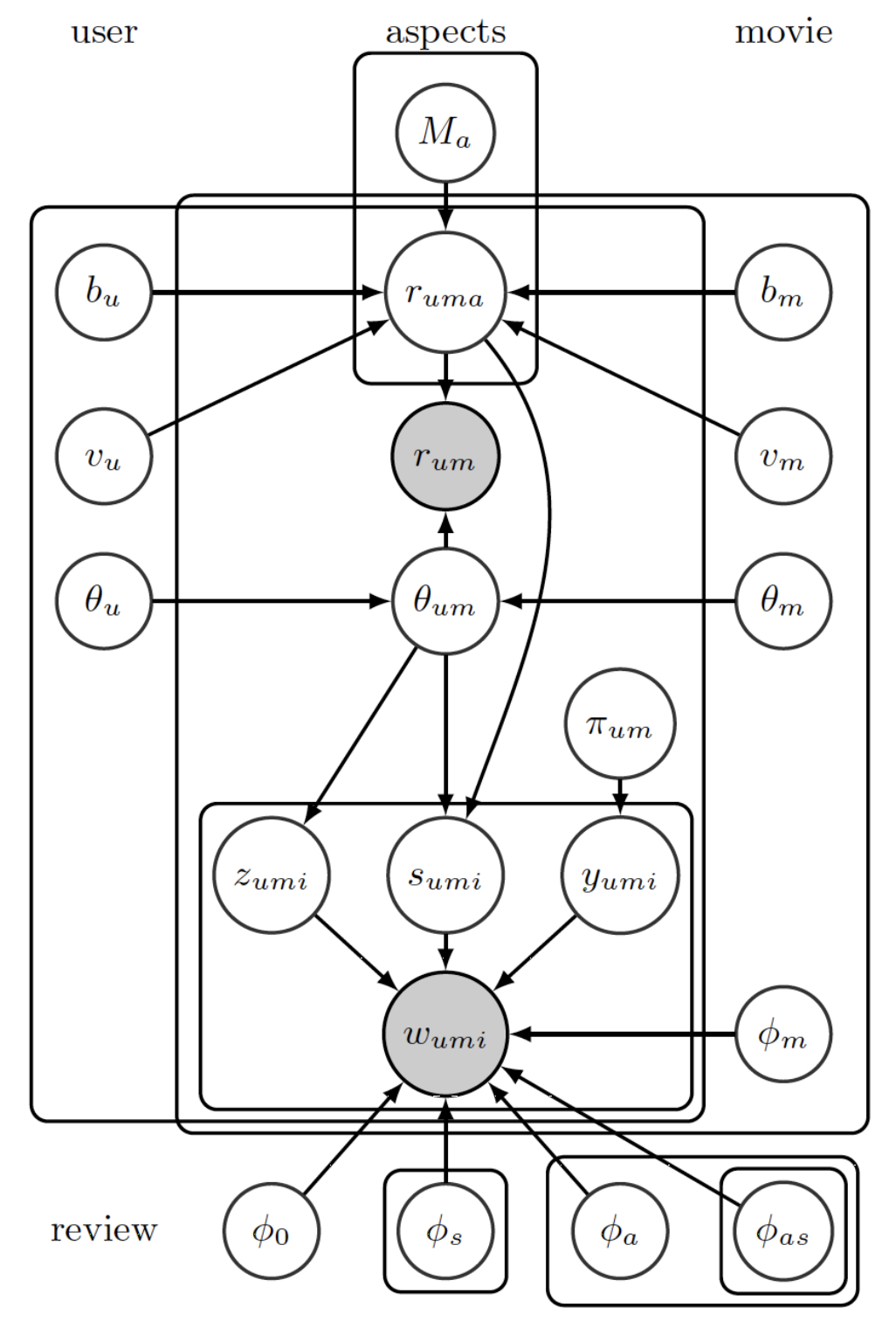
Jointly Modeling Aspects, Ratings and Sentiments With Temporal Dynamics
In this work, we first implement and then propose an extension to the paper Jointly Modeling Aspects, Ratings and Sentiments for movie recommendation (JMARS) by carefully incorporating temporal dynamics into the model and empirically showing that it provides an improvement of around 0.9% on two datasets. We replicate the quantitative results and qualitative analysis provided in the original paper and furthermore, provide some analysis from the extended model.
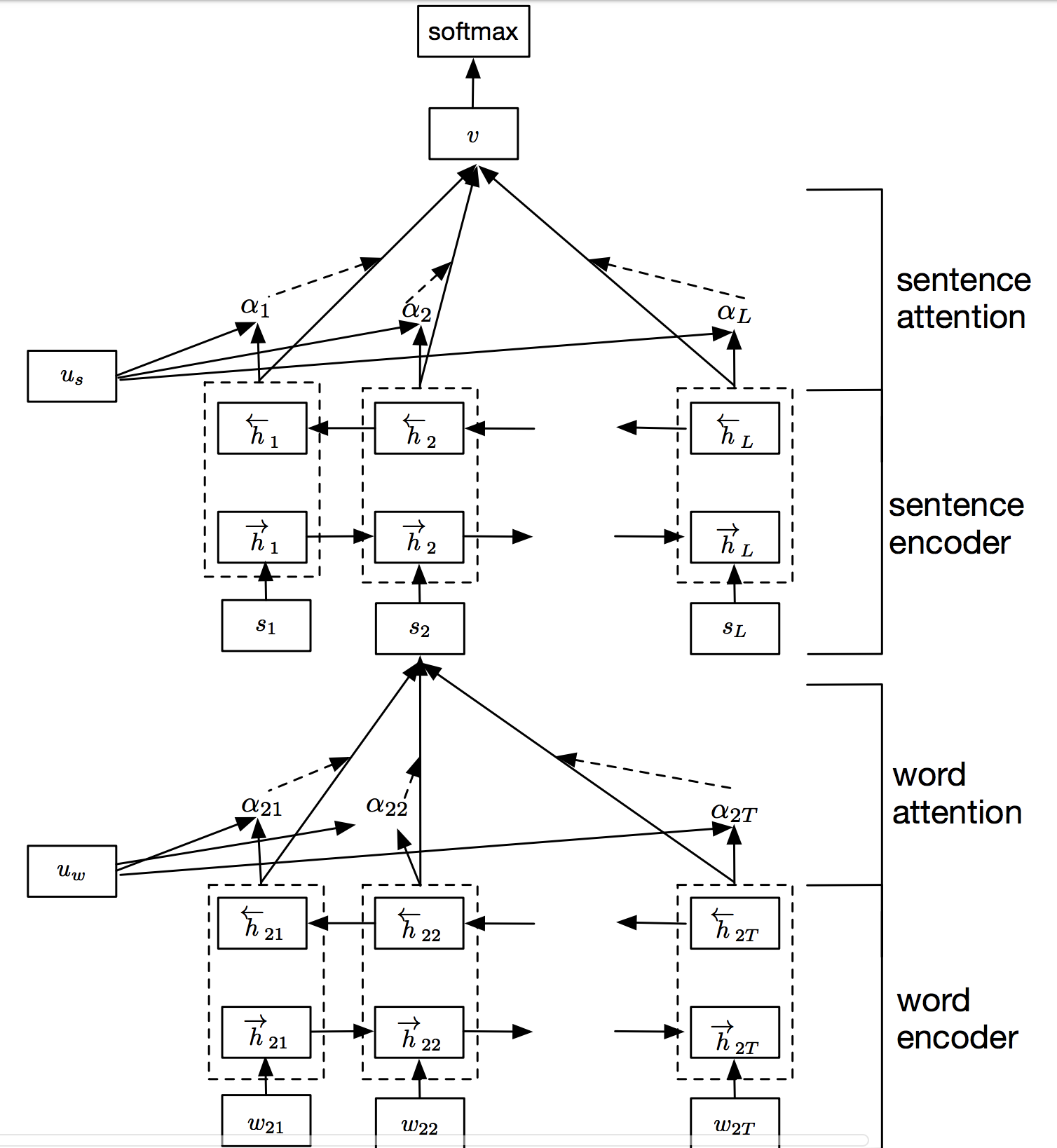
Hierarchical Attention Network for Rating Prediction
Implementation of a hierarchical attention network for document classification based on this paper. The model has two distinctive characteristics: (i) it has a hierarchical structure that mirrors the hierarchical structure of documents; (ii) it has two levels of attention mechanisms applied at the word and sentence-level, enabling it to attend differentially to more and less important content when constructing the document representation.
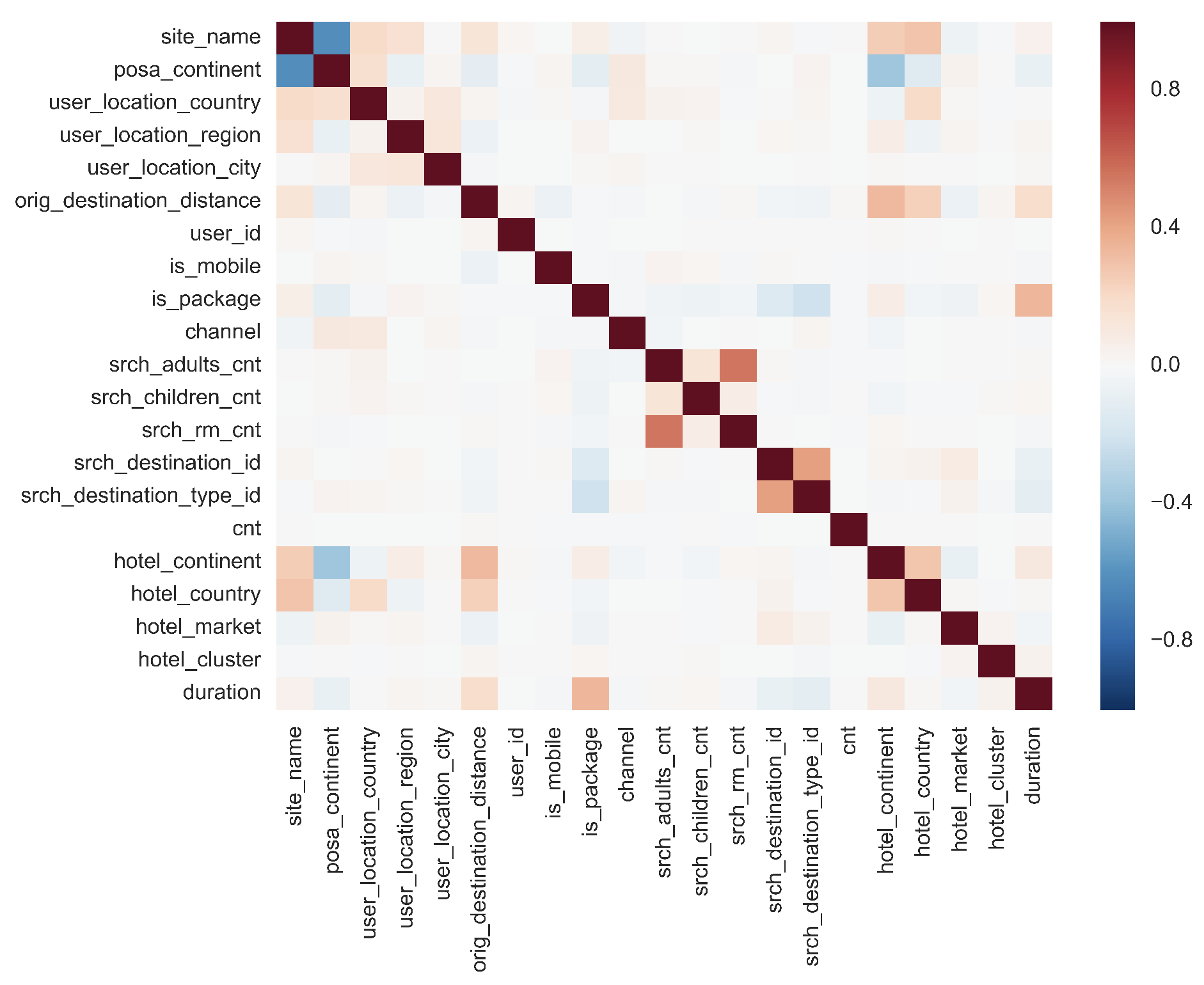
Hotel Recommendation System
We explore Expedia's online hotel booking dataset to recommend hotels to users based on their preferences. The dataset was made available by Expedia as a Kaggle challenge. In this project, our aim is to contextualize customer data and predict the likelihood a user will stay at 100 different hotel groups. The goal is to provide not just one recommendation but to rank the predictions and return the top five most likely hotel clusters for each user’s particular search query in the test set. We use multiple models and techniques to arrive at our best solution. This includes (1) An ensemble of four different models (random forests, SGD classifier, XG Boost and Naive Bayes), (2) XG Boost that is preceded by completion of distance (between user and their potential destination) matrix - an important feature in the dataset which is currently incomplete, (3) Data leakage solution which takes advantage of the fact that there is a potential leak in the data provided to us, and (4) a mixture of the methods in (1) and (3).

Ensemble of Convolutional Neural Networks for Traffic Lights Recognition
We developed an ensemble of multiple Convolutional Neural Networks (CNN) where each CNN is built with the motive of giving a superior performance while keeping the model size small. The sub-models have no more than 490k parameters but each achieves an accuracy greater than 87%. Models are tested and trained on the Nexar traffic lights challenge dataset with the aim of correctly recognizing the presence and state of traffic lights in images taken by the drivers using the Nexar app. We show that minimizing the number of parameters in each of the models allows quick training even when computational resources are not abundant. We also perform localization experiments using Faster R-CNN on a separate annotated dataset (UCSD traffic lights dataset) to demonstrate high performance for classification and detection tasks. The output is highly desirable and useful for deployment onto actual vehicles where the memory is limited and traffic light inferences have to be made in real-time.

Music Generation using Character-level RNN
We train a Recurrent Neural Network (RNN) to learn the structure of music files in ABC format and then generate a music file based on what the model learns. We built a simple network with 1 hidden layer and fed the input sequence of length 25 to predict the next character in sequence. We experiment with different parameters like temperature, dropout, the number of neurons in the hidden layer and the effect of optimizers and observe their effect on model’s learning behavior. We also visualize the activations of neurons in RNN to understand the purpose of each hidden unit in the network.

Prediction of Helpfulness of Reviews
This project was done as a part of a Kaggle competition. The dataset was Amazon product reviews dataset with 200,000 training examples and 14,000 test examples. Our aim was to predict the number of helpful votes a review would get out of all the votes given to the review. Accuracy was measured in terms of the mean absolute error (MAE). After pre-processing and cleaning of the data, I incorporated features which were the polynomial interactions (of degree 2) of some of the best attributes in the data and consequently applied linear regression. Please follow the link to the project to see my report where I’ve described my approach and model in detail. I ended up in top 12% at the end of the competition.
Product Rating Prediction
This project was done as a part of a Kaggle competition. The dataset was Amazon product reviews dataset with 200,000 training examples and 14,000 test examples. Our aim was to predict the rating user would give to an item. Accuracy was measured in terms of the mean squared error (MAE). I employed matrix factorization method with user and item biases to predict the missing ratings. I ended up in top 17% at the end of the competition.
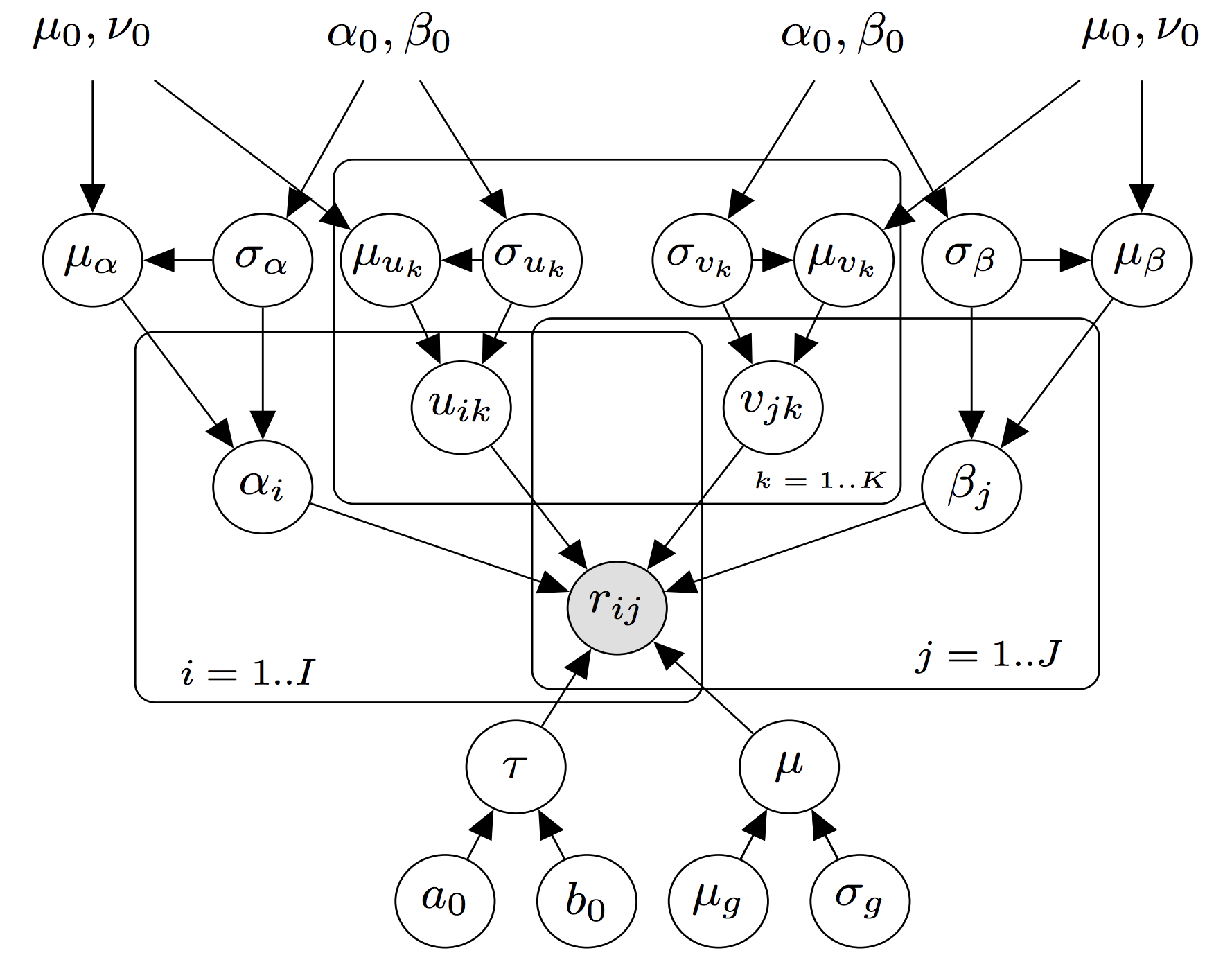
Scalable Bayesian Matrix Factorization
Factor based models have been used extensively in recommender systems based on collaborative filtering. Matrix Factorization is the simplest and most well studied factor based model and has been applied successfully in several domains. A fully Bayesian treatment of Matrix Factorization avoids the problem of overfitting and doesn't entail manual tuning of parameters, but the existing Bayesian Matrix Factorization method, based on the Markov-Chain-Monte-Carlo technique, has cubic time complexity with respect to the dimension of latent factors, which makes it difficult to apply it to very large datasets. In this project, we have proposed a scalable Bayesian Matrix Factorization approach, again based on the Markov-Chain-Monte-Carlo technique, but which has linear time complexity with respect to the dimension of latent factors and linear space complexity with respect to the number of training instances. Also, we show through extensive experiments on three sufficiently large real-world datasets that our method incurs only a small loss in the performance and takes much less time as compared to the baseline method for higher latent dimension.

Scalable Variational Bayesian Factorization Machine
Support Vector Machines (SVMs) are one of the most popular predictors in machine learning which work on the generic features extracted from the data. But SVMs fail on very sparse data as encountered in applications like recommender systems. On the other hand, factorization models like matrix factorization and tensor factorization consider interactions among all the variables and provably work well on sparse and high-dimensional data. However, designing a factorization model specific to a given problem requires expert’s knowledge. Factorization machine (FM) is a generic framework which combines the advantages of feature based representation of SVMs and the interaction of variables in factorization models. In this work, a scalable variational Bayesian inference algorithm for FM is developed which converges faster than the existing state-of-the-art Markov-Chain-Monte-Carlo based inference algorithm. Additionally, for large scale learning, a stochastic variational Bayesian algorithm for FM is also introduced which utilizes stochastic gradient descent (SGD) to optimize the lower bound in variational approximation. The variational method based on SGD outperforms existing online algorithm for FM as validated by extensive experiments performed on numerous large-scale real world datasets.